“I am suffering from these tools, they consume a lot of memory and they need a lot of space” or ” I am overwhelmed with the features of this tool, somehow I find myself lost and I can’t figure out how to do simple tasks”.. Does this sound familiar to you? Many tools nowadays offer great features but we need terabytes of storage to have them locally and a powerful device is needed too. Well, today is your lucky day if you are dealing with databases. Have you heard about Azure Data Studio? In this post, I will give you some tips to improve your work performance with Azure Data Studio. Here is the structure of this blog post.

Table of contents
Connect to multiple Azure accounts
Introduction:
Azure Data Studio was firstly introduced in Pass Summit 2017 (it was called SQL Operations Studio). It is a cross-platform tool for database design and operations. If you are friendly with Visual Code, you will love Azure Data Studio. It is a lightweight version, with the necessary tools and you won’t be overwhelmed with many features such as the case with SSMS (Microsoft SQL Server Management Studio).
Overview:
Azure Data Studio is a light-weight cross-platform database management tool for Windows, MacOS, and Linux. It is free (no license needed) and it is an open source project. Azure Data Studio is based on VS Code and MSSQL extension in VS Code, written in ElectronJS. You can report bugs, request new features and contribute to the project. Extensions are an amazing feature of Visual Code, so does the Azure Data Studio, you can add extensions but they are not that much (for the moment 😉 ).
It supports Azure SQL Database, Azure Data Warehouse, MSSQL Server whether running in cloud or on-premises. T-SQL Query is mainly supported by autosuggestions, formatting and advanced coding features. Meanwhile, it still supports other languages such as JSON, XML, Python, SQL, yaml, dockerfile… In addition, you can work with workspaces, folders. Source Control (GIT) is integrated, so no problem with managing your files. This is an amazing feature especially for those who opt for CI/DI pipeline using Azure DevOps. Speaking of Azure, Azure Resource Explorer is a panel in Azure Data Studio that allows you to connect to your Azure account(s) and work with your different subscriptions. If you work with PowerShell or different shells, you can do it also in Azure Data Studio thanks to the internal terminal as it is the case with Visual Code. It has another bunch of features.
The Queen of Vermont and Entity Framework @Julie Lerman, a Microsoft Regional Director and MVP, wrote two blog posts in MSDN magazine about Azure Data Studio: Data Points – Visual Studio Code: Create a Database IDE with MSSQL Extension(June 2017) and Data Points – Manage Data Across Multiple Sources with Azure Data Studio(December 2018). So, I advise you to read them because I am not repeating what she has already written (I don’t have her level of knowledge and skills so I won’t make it perfect the way she does). Meanwhile, I will give you some tips that will help you.
UI :
The User Interface of Azure Data Studio is similar to the one of Visual Code. It is simpler and not overwhelmed with menus. It has the classic left sidebar as it is the case in VS Code. You can split the window the way you want (literally limitless splitting). Figure 1 shows you how to change theme color.

Export User Settings:
Most of us have at least 2 devices: a business laptop, and personal laptop/tablet. Let’s say you tested Azure Data Studio in your personal device and customized it. Then, you decided to install it in the second device with the same customized settings. I got you covered! It is easier than you think. I will recreate the two first steps in the Figure 2. (1) Open user settings by clicking on the Settings logo in the bottom left corner and then settings, you can open it from command palette: open it using the keyboard shortcut CTRL+comma. (2) Now, move the cursor over the tab and give it a right click, then “Reveal in Explorer”. (3) Copy the file settings.json and send it to your work device. (4) Repeat the same first steps in your work device and finish it by replacing the current settings.json file with the other file. Done.

Change Terminal Shell:
The first time you install Azure Data Studio, you will have to choose default terminal shell. Later on, when you click on the add new terminal icon, you will get the same terminal shell, but what if I want to use Powershell and Cmd at the same time. To do so, you need to change the default terminal shell by opening the Command Palette (CTRL+Shift+P), then type “Select Default Shell” and hit the enter key. You can change the shell type by selecting one from the given list. There is another way to do it: Open User Settings (the first step in the previous Tip), then search for :
"terminal.integrated.shell.windows": “Shell path”
You have to change the path and you are ready to go.
For example, my default terminal shell is CMD so it looks like this
"terminal.integrated.shell.windows": "C:\\WINDOWS\\System32\\cmd.exe"
In order to change it to PowerShell, I only replace the Shell path string
"terminal.integrated.shell.windows": "C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\powershell.exe"
*You have to repeat these steps every time you want to change the shell.
Subscriptions Filter:
It is a simple tip, but it is worth it in case you have many subscriptions. Azure Data Studio allows multiple linked accounts, that means you can connect to different Azure accounts and use all the resources at the same time, which is really COOL. However, you may have many subscriptions and you will not use all of them. To get rid of the unnecessary ones, you use the subscription filter by hovering over the account as it is demonstrated in Figure 3.

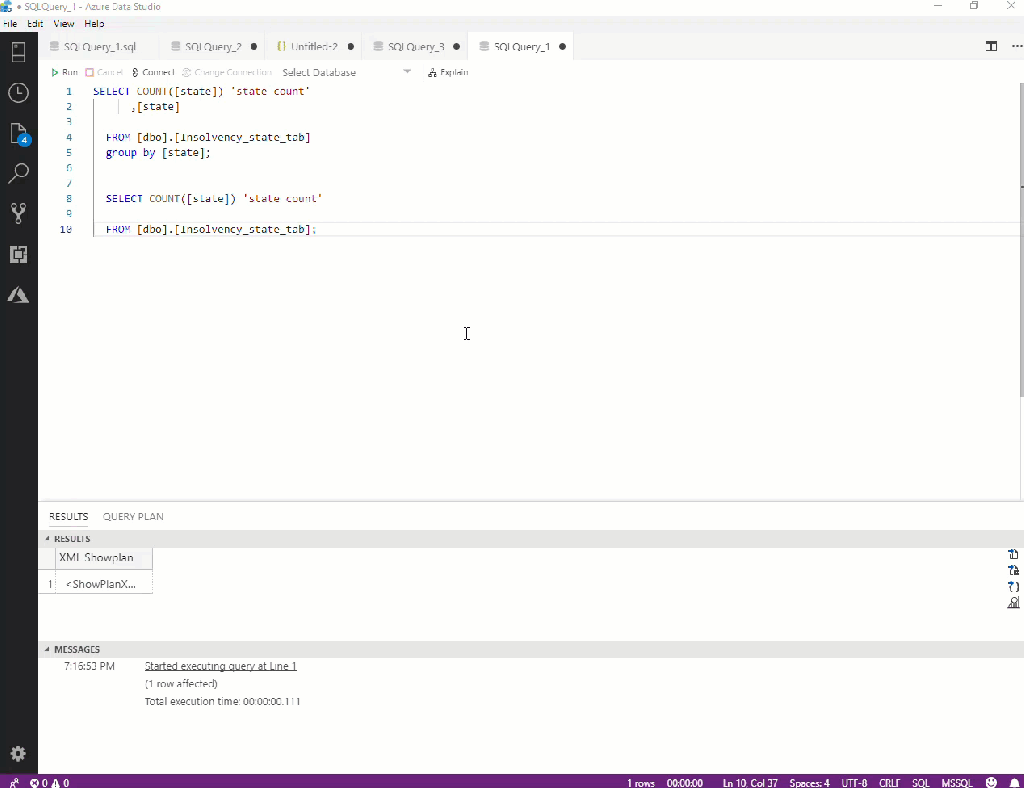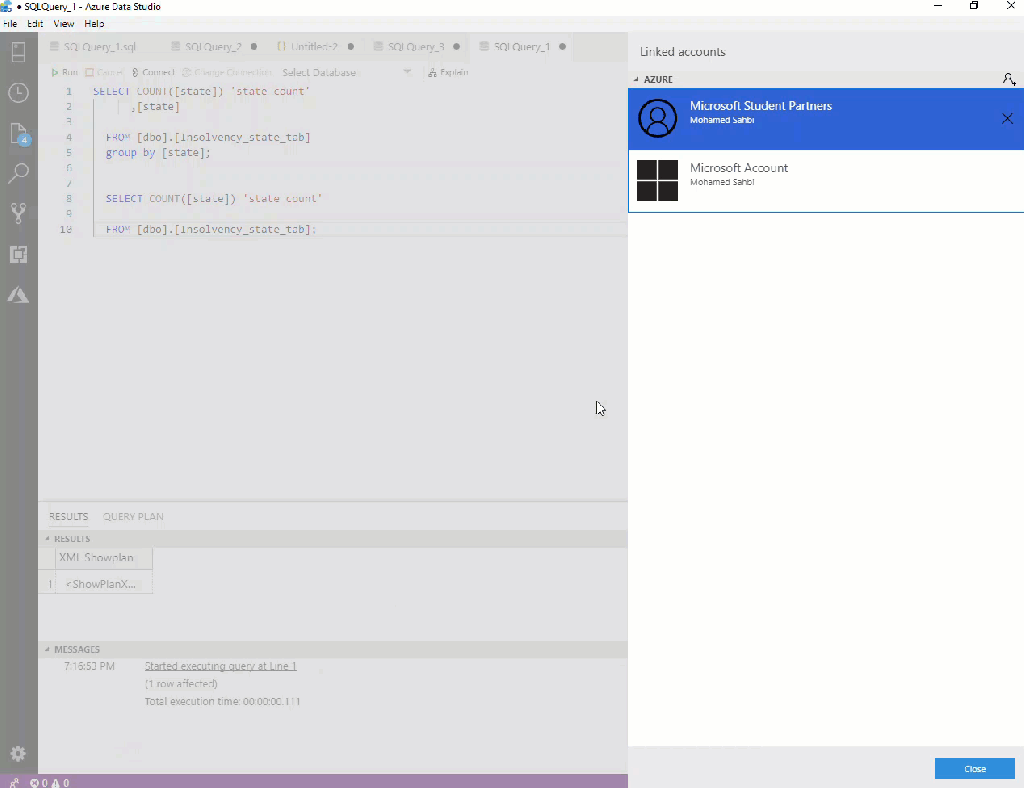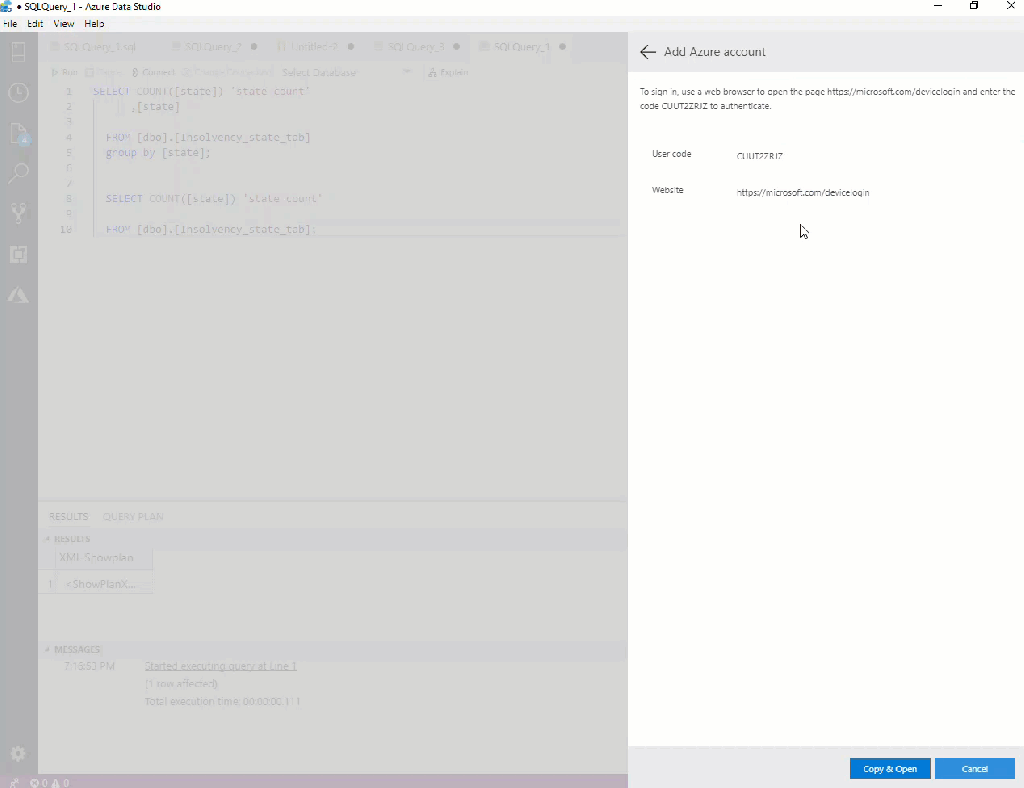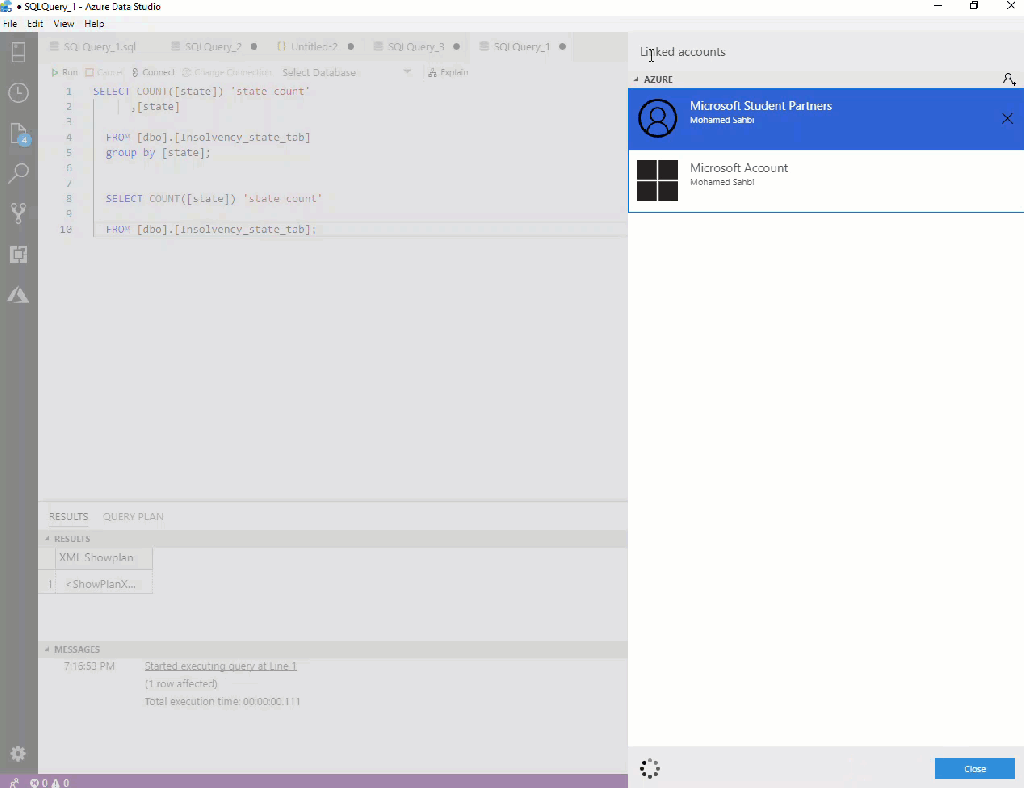
Connect to multiple Azure accounts:
I just discovered it while writing the Subscriptions Filter tip that it may be tricky to connect to a second or third Azure account. You need to click on the person icon (bottom left corner of the window). Figure 4 shows you the way.
Run a script from file:
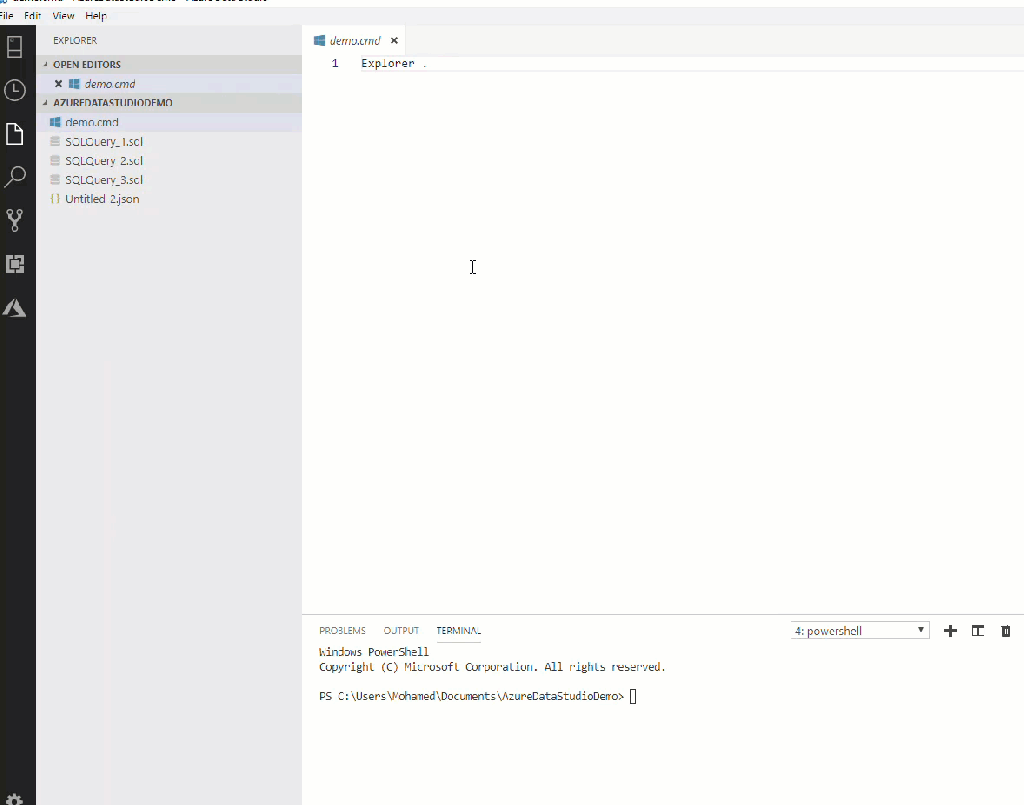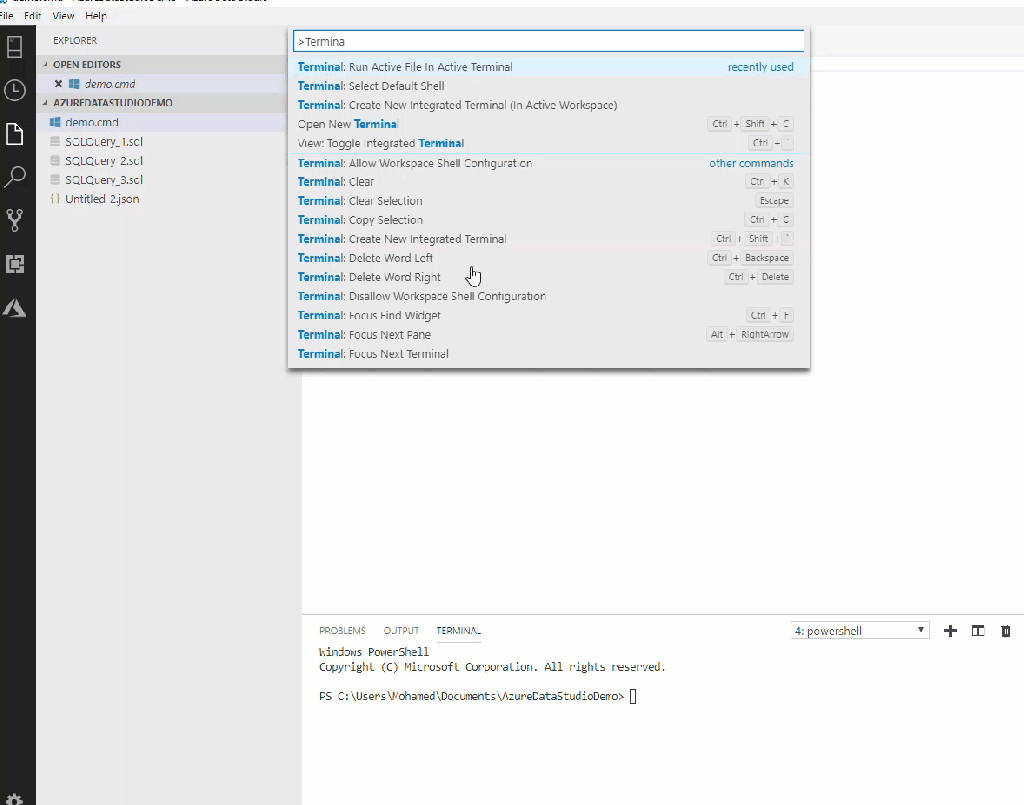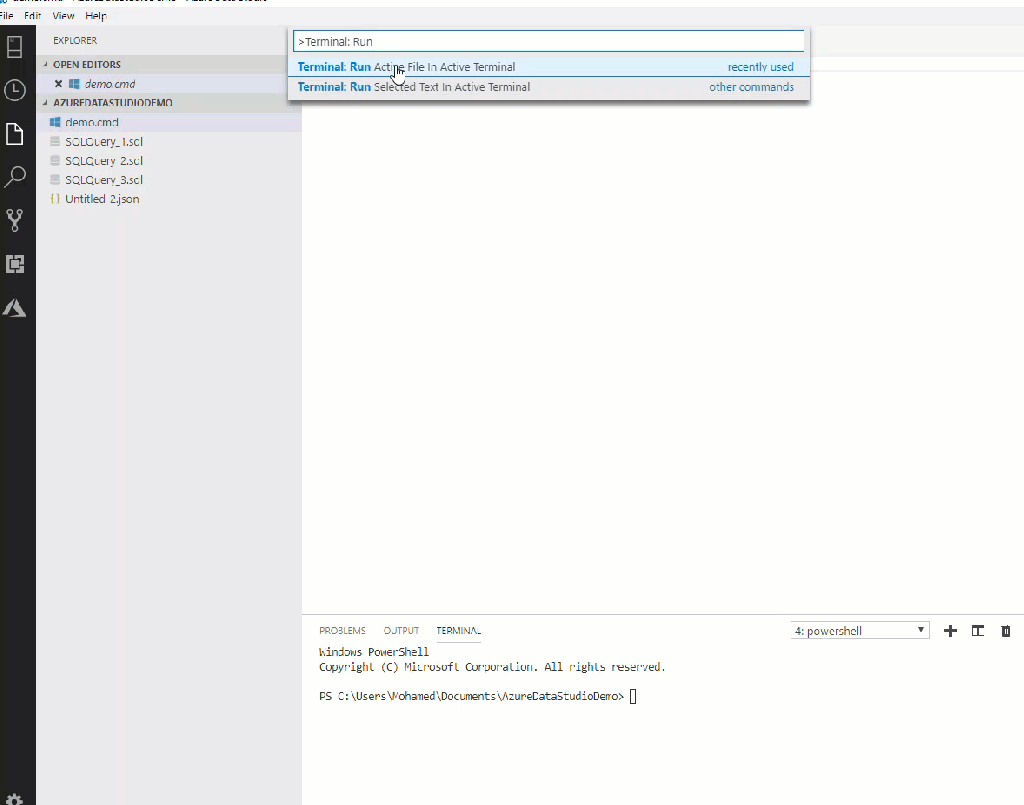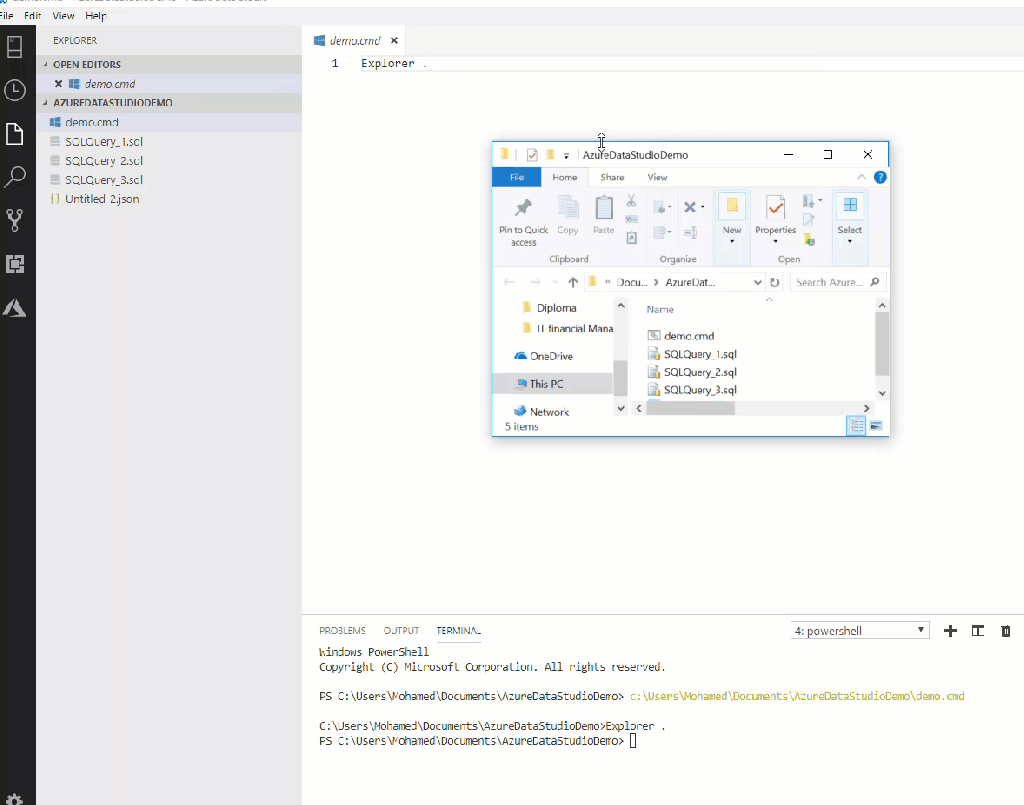
Internal terminals, an amazing feature that Azure Data Studio has. It makes the life of DB Admins easier, you don’t need to open many apps and windows, just all in one tool is needed. We all know that we can open a folder or a workspace in Explorer (Explorer panel of Azure Data Studio, not Windows Explorer), you have some file scripts and you want to run it. There is command provided for this task to run the active file or just the selected text in the active terminal. In Figure 5, you can see how it works. This command doesn’t have a keyboard shortcut by default (you can add one by editing the keyboard shortcuts 😉). To make it work, open the command palette and type:
Terminal: Run Active File in Active Terminal
Or
Terminal: Run Selected Text in Active Terminal
~*~*~*~*~*~
There are other features you will enjoy in Azure Data Studio and they will improve your work such as Auto Save (you don’t have to save changes with Ctrl+S every time), the process Explorer or peek a definition, etc.
The purpose of this blog post was showing some cool features of this great tool. You may notice that I did not mention anything related to working with databases, queries, or extensions; they need another blog post. For now, you can start with the Quickstarts Tutorials and the official documentation. If you don’t have it yet, you download it here.
Contribute
Please help the community by giving your feedback and contributing on GitHub.
— — — —
References
To write this blog post, I used the official documentation of Azure Data Studio, Julie Lerman blog posts in MSDN Magazine and two blogs from VisualStudioMagazine (here and here).

